

Python采集后HTML解析
思考后确定获取目标
假如我们确定一个我们需要采集的目标信息,可能是一组统计数据、或者一个 title等,但是此时这个目标可能藏的比较深,可能在第20层的标签里面,你可能会用下面的方式去抓取:
| bsObj.findAll("table") [4].findAll("tr") [2].find("td").findAll("div") [1].find("a") |
同时还有一个问题,加入网站发生细微的变化。我们的代码不仅影响美观还回影响整个爬虫网络。这样的情况我们应该怎么做呢?
尝试“打印此页”的链接,或者看看该网页的移动版是够更加友好,请求的时候将请求头设置为移动端的状态。
寻找隐藏在JavaScript文件里的信息。网站的某些数据可能隐藏在JavaScript文件中。
可以试试其他的网站资源。
BeautifulSoup使用
上一篇我们学会了如何安装和运行BeautifulSoup,现在我们逐步深入,学习通过属性查找标签的方法、标签组、标签解析树的导航过程。
每个网站都有层叠样式表(也就是我们说的CSS),它对于爬虫而言有一个最大的好处就是能够让HTML元素表现出差异化。
例如某些标签是下面这样的:
| <span class="green"></span> |
或者这样的:
| <span class="red"></span> |
爬虫可以根据class的属性值去区分不同的标签。例如:我们可以只抓取红色的字。
下面我们以这个网站为例来创建一个网络爬虫。
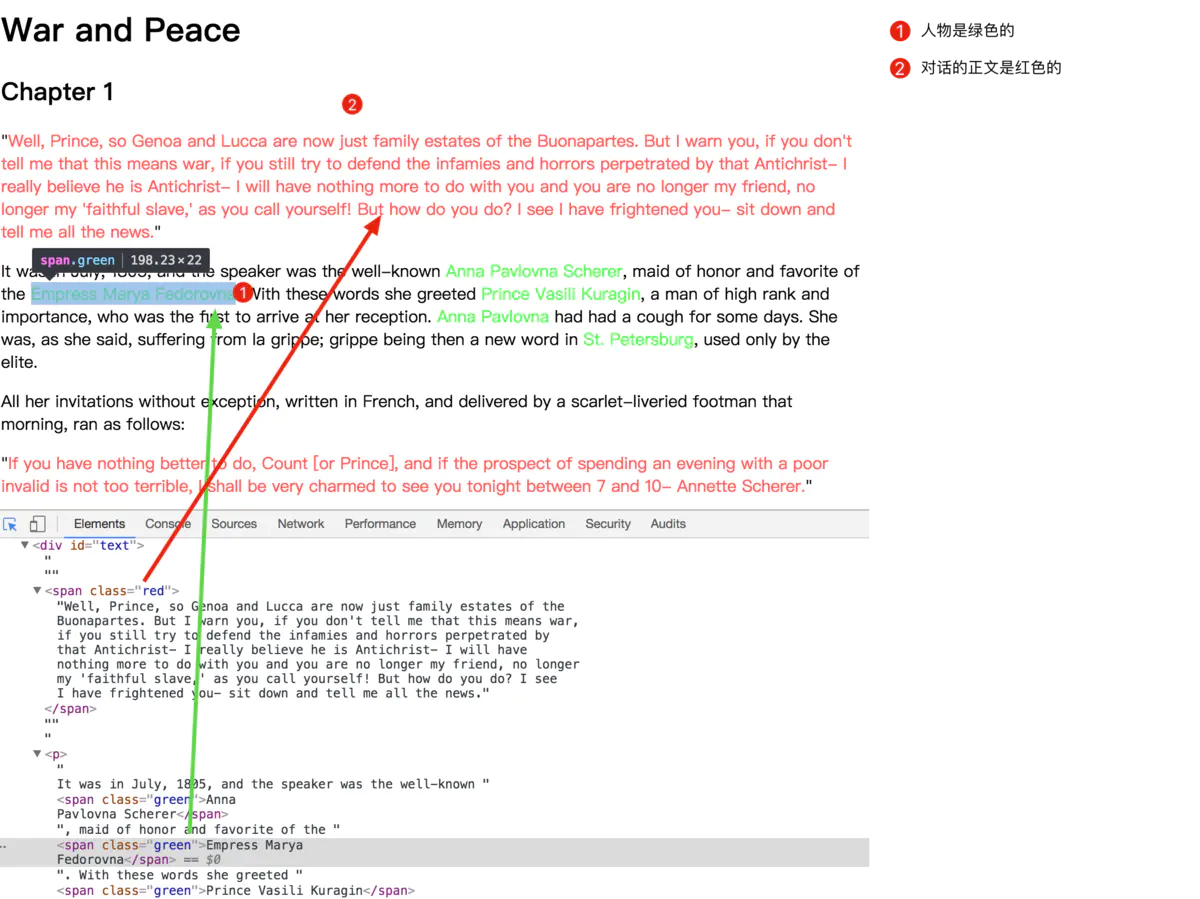
网站解释说明
通过上图可以知道红色的为对话正文部分,绿色为姓名的信息。现在可以创建一个简单的BeautifulSoup对象。
| from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen (" http://www.pythonscraping.com/ pages/warandpeace.html") bsObj = BeautifulSoup(html,'lxml') # 获取了html的所有信息 |
通过BeautifulSoup对象,我们可以用findAll函数抽取只包含在<span class="green"></ span>标签里的文字,这样就会得到一个人物名称的 Python列表。
| nameList = bsObj.find_all('span',{"class":"green"}) #获取span标签的class为green的所有姓名 for name in nameList: # 遍历取值 print(name.get_text()) |
然后运行得到的就是所有的姓名列表。
get_text()使用场景主要是处理一个包含许多超链接、段落和标 签的大段源代码,它就会吧这些超链接和段落以及标签都清理掉。也就是说它会把你正在处理的 HTML文档中所有的标签都清除,然后返回一个只包含文字的字符串。
BeautifulSoup的find()和find_all()
BeautifulSoup里的find()和find_all()可能是你最常用的两个函数。借助它们,你可以通过标签的不同属性轻松地过滤HTML页面,查找需要的标签组或单个标签。
BeautifulSoup文档地址:http://beautifulsoup.readthedocs.io
find()函数语法:
| find( name , attrs , recursive , string , **kwargs ) |
find_all()函数语法:
| find_all( name , attrs , recursive , string , **kwargs ) |
搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件。
name参数可以查找所有名字为name的tag,字符串对象会被自动忽略掉。搜索 name参数的值可以使任一类型的过滤器,字符串,正则表达式,列表,方法等。
attrs参数定义一个字典参数来搜索包含特殊属性的tag。
通过string参数可以搜搜文档中的字符串内容,与name参数的可选值一样。
keywork参数:如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字tag的属性来搜索。
find_all()方法返回全部的搜索结构,如果文档树很大那么搜索会很慢。如果我们不需要全部结果,可以使用 limit参数限制返回结果的数量.效果与SQL中的limit关键字类似,当搜索到的结果数量达到limit的限制时,就停止搜索返回结果。
find 等价于 find_all 的 limit 等于 1 ;
调用tag的 find_all()方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False。
其他BeautifulSoup对象
NavigableString对象:表示标签里面的文字;
Comment对象:用来查找HTML文档的注释标签。例如:``
导航树
导航树解决的问题是通过标签在文档中的位置来查找标签。以该网站为例。
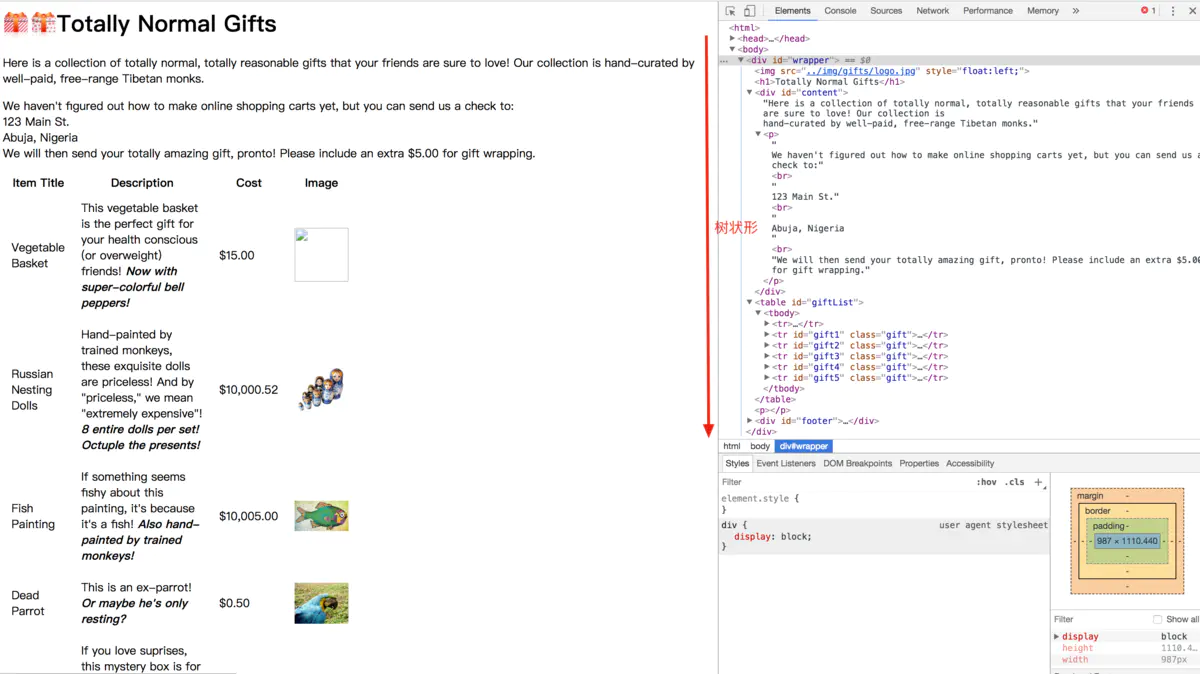
示例网站和源码展示
第一类,处理子标签和其他后代标签。
子标签就是一个父标签的下一级,而后代标签是指一个父标签下面所有级别的标签。所有的子标签都是后代标签,但不是所有的后代标签都是子标签。例如:
tr标签是tabel标签的子标签,而 tr、th、td、img和 span标签都是 tabel 标签的后代标签。
一般情况下,BeautifulSoup函数总是处理当前标签的后代标签。
例如根据示例网站我们需要找到文档中第一个div标签,然后获取这个div后代里面所有的img标签。
| from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen ('http://www.pythonscraping.com /pages/page3.html') for child in bs.find('table', {'id':'giftList'}).children: |
输出的结果就是打印 giftList 表格中所有产品的数据行。
第二类,处理兄弟标签。
BeautifulSoup的next_siblings()函数可以让收集表格数据成为简单的事情,尤其是处理带标题行的表格:
| from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen('http://www.pythonscraping.com/ pages/page3.html') for sibling in bs.find('table', {'id':'giftList'}).tr.next_siblings: |
输出的结果是打印产品列表里的所有行的产品,第一行表格标题除外。
第三类,父标签处理。
抓取网页的时候我们抓取父标签的情况比较少,但是不排除有这样的情况存在。例如,我们要观察网页的内容。这里就需要连个两个函数parent 和 parents。
| from urllib.requesturllib. import urlopen from bs4 import BeautifulSoup html = urlopen('http://www.pythonscraping.com/pages/page3.html') print(bs.find('img',{'src':'../img/gifts/img1.jpg' }).parent.previous_ sibling.get_text())
|
上述代码的结果是img1图片的价格。
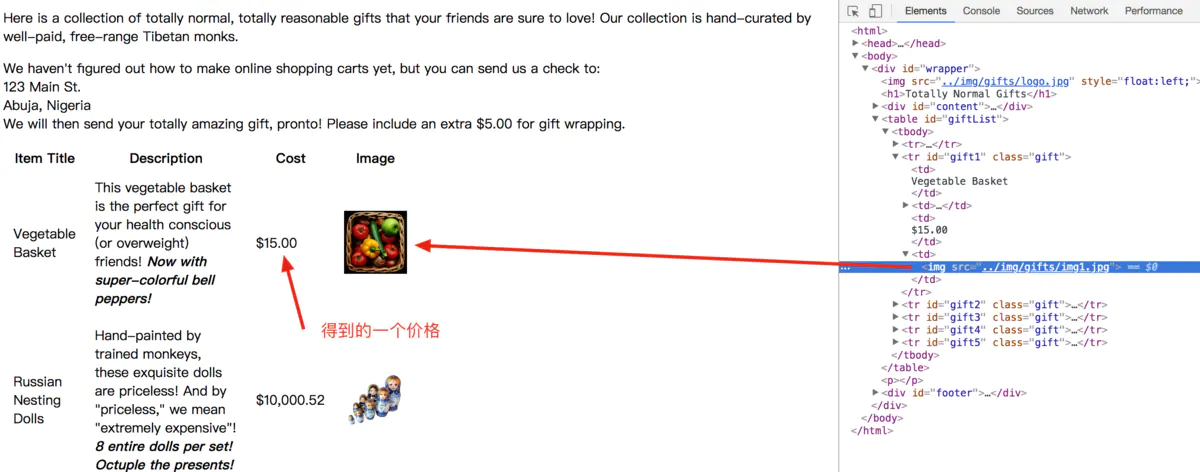
图片价格信息
正则表达式
正则表达式个人认为比较简单,就跟学习英语一样,只要不断的去用就了解了。贴上原图可查阅即可。关于正则的相关基础知识可以看看我推荐的网站了解一下,或者可以关注我,后续专门写一个正则表达式入门的文章。
或者用下面的这张图,然后跟着去套一些例子。

正则表达式常用符号
正则表达式和BeautifulSoup
结合正则表达式,来实现一下具体的例子,可能更容易理解一些。我们获取刚刚网站的所有图片,首先打开源码分析一下页面。
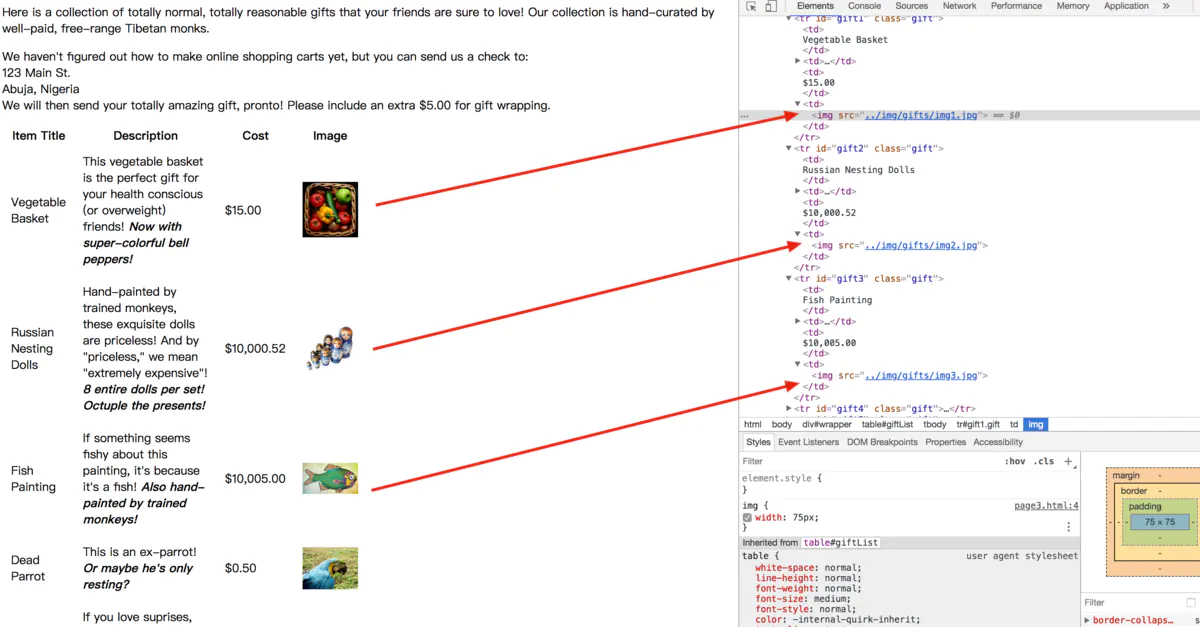
所有图片路径
我们发现所有的图片都是以../img/gifts/img开头,以.jpg 结尾。那么就用正则去匹配一下。匹配规则如下:
| \.\.\/img\/gifts/img.*\.jpg |
结合BeautifulSoup对象我们可以尝试用代码试一下:
| from urllib.request import urlopen from bs4 import BeautifulSoup import re html = urlopen('http://www.pythonscraping.com/pages/page3.html') |
运行的结果:
| ? url python pareten2.py ../img/gifts/img1.jpg ../img/gifts/img2.jpg ../img/gifts/img3.jpg ../img/gifts/img4.jpg ../img/gifts/img6.jpg
|
这就是网站的所有图片的相对路径,以后可以用这样的方法去匹配视频网站的路径,然后下载啦。
获取属性
在网络数据采集时你经常不需要查找标签的内容,而是需要查找标签属性。比如标签 <a>指向 的 URL 链接包含在 href属性中,或者 <img>标签的图片文件包含在 src 属性中。
对于一个标签对象,可以用myTag.attrs获取它的全部属性,要注意这行代码返回的是一个 Python 字典对象,可以获取和操作这些属性。例如要获取图片的资源位置 src,可以用myImgTag.attrs["src"]获取。
Lambda表达式
Lambda表达式本质上是一个函数,可以作为其他函数的变量使用;也就是说,一个函数不是定义成 f(x, y),而是定义成 f(g(x), y),或 f(g(x), h(x)) 的形式。
BeautifulSoup 允许我们把特定函数类型当作 findAll 函数的参数。唯一的限制条件是这些 函数必须把一个标签作为参数且返回结果是布尔类型。BeautifulSoup用这个函数来评估它遇到的每个标签对象,最后把评估结果为“真”的标签保留,把其他标签剔除。
来源:

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~

